
Introduction
Neural Networks have been at the foreground of Computer Science over the last decade, with applications varying from hand writing recognition, audio and video interpretation and facial recognition. With theory based on the biological function of the brain, however, building a neural network is no simple task. Much like teaching a baby through repeated exposure, training an artificial neural network requires large amounts of training data, extensive computing power, is time consuming and can be very expensive.
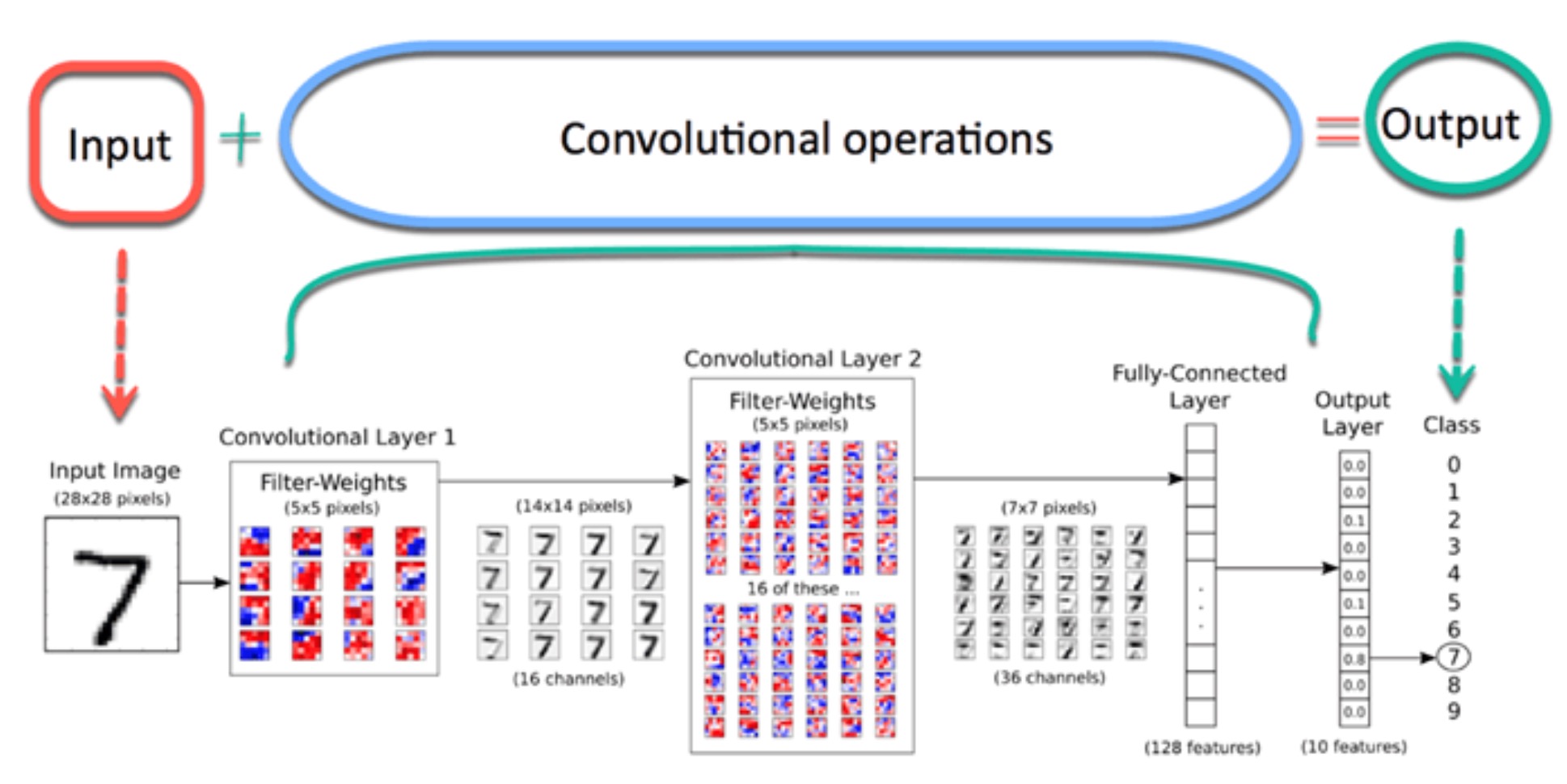
While there are different types of neural networks, we focus our attention on Convolution Neural Networks (CNN), which are primarily used in computer vision and image classification tasks. CNN’s are composed of a series of layers designed to extract and filter relevant features from an input image, passing them to the next layers for further processing via a series of neurons. Similarly to how the biological visual system work, the input image is broken into overlapping regions known as receptive fields, from which these features are extracted. Neurons respond to stimuli from these regions and transfer data to the next layer to extract more complex features, until it output a classification.
Since CNN’s can be complex and time-consuming to build and train from scratch, this process can be bypassed through the use of transfer learning. Transfer learning employs the knowledge of a pre-trained model in order to extract features from a new set of data it has never seen before. This can be likened to the situation where a person who speaks French can apply that base knowledge to learn Spanish, which has similar linguistic roots. Keras neural networks package offers a series of pre-trained models that can be applied for transfer learning, but also allows users to build neural frameworks from scratch, in conjunction with TensorFlow.
In this project we use the Keras package for R in conjunction with TensorFlow to build and train a model to recognize facial expressions. Our data, obtained from Kaggle, contains 7 classes of facial expressions: Angry, Disgust, Fear, Happy, Neutral, Sad and Surprise, already separated into training and validation sets. Due to limitations in computing power and time, we built our model to strictly recognize Happy or Sad expressions. Our initial attempt sought to use transfer learning to compare the ability of 3 pre-tained models, InceptionV3, resNet50 and VGG16, to learn how to recognize these expressions, but were unsuccessful. Ultimately, we built a model for scratch, which we describe below, and created a Shiny app where a user can. . . ..(input an image to see whether model accurately identfies a happy or sad expression.)
Data Preparation
Our dataset had been the previous split into training and test sets, and to reduce the amount of computational power and time needed to train our neural network, we limited our expression classes to “Happy” and “Sad”. Our training set was composed of 7164 Happy images and 4938 Sad images, which our validation set was composed of 1825 Happy images and 1139 Sad images, all of size 48 x 48 pixels and greyscale. To begin, these two expression classes were assigned a variable called “face_categories”, with the length of this vector indicating the number of output classes.
Our pre-processing parameters were then defined. Though our images were sized at 48 x 48 pixels, we set our standardized image input size at 244 X 244 pixels, because. . . . . . . . . . . . ..Explain why we increase the size of the image, how does this affect the reduction of computation complexity. Since our images were greyscaled we set the channel number to 1. The directory from which the training and validation images would be called was then defined, and their corresponding image data generators were set to normalize each pixel from values between 0 and 255 to values between 0 and 1. The images were then loaded from the assigned path, applying all the defined pre-processing parameters that would allow the data to then be passed into the convolutional layers.
# List of categories
face_categories <- c("happy", "sad")
# Number of output classes
output_n <- length(face_categories)Our pre-processing parameters were then defined. Though our images were sized at 48 x 48 pixels, we set our standardized image input size at 244 X 244 pixels, because Explain why we increase the size of the image, how does this affect the reduction of computation complexity. Since our images were greyscaled we set the channel number to 1. The directory from which the training and validation images would be called was then defined, and their corresponding image data generators were set to normalize each pixel from values between 0 and 255 to values between 0 and 1. The images were then loaded from the assigned path, applying all the defined pre-processing parameters that would allow the data to then be passed into the convolutional layers.
img_width <- 244 #Add explanation for increasing size above
img_height <- 244
target_size <- c(img_width, img_height)
channels <- 1 # one channel because images aew greyscaled
# Path to image folders
train_image_files_path <- choose.dir()
valid_image_files_path <- choose.dir()
# Normalizing/scaling the image matrix (we need to scale each pixel to decrease computational expensiveness of neural network)
train_data_gen = image_data_generator( rescale = 1/255)
valid_data_gen <- image_data_generator( rescale = 1/255)# Loading training images
train_images <- flow_images_from_directory(train_image_files_path, train_data_gen,
target_size = target_size, class_mode = "categorical", classes = face_categories, color_mode = "grayscale", seed = 42)
# Loading test images
valid_images <- flow_images_from_directory(valid_image_files_path, valid_data_gen, target_size = target_size, class_mode = "categorical", classes = face_categories, color_mode = "grayscale", seed = 42)Model Creation
With the test and training images pre-processed, we were then ready to set our training and validation parameters. Passing a large dataset into the training algorithms at once is inefficient, therefore we broke the total set into smaller batches. To optimize the model, the data needs to pass through the algorithm several times, as determined by the number of epochs. The number of epochs selected helps to reduce the possibility of over- or underfitting the model, where too few epochs lead to an underfit, or too many can lead to an overfit. For our data, we selected a batch size of 32 to be integrated over 10 epochs.
To build the model from scratch we used a sequential Keras model, allowing us to define a series of linearly stacked layers. These layers are defined and described below.
First Convolutional Layer
The first convolutional layer passes the pre-processed input images through 32 3 x 3 pixel filters, with a default stride of 1. This process inevitably reduces the width and height of the input, thus by setting padding = “same”, we are ensuring that the output maintains the input size, by padding the outer edges of the feature map with zeros. The output feature map of this layer is then passed to the Relu activation function to convert all negative valued pixels into zeros.
Second Convolutional Layer
The second convolutional layer uses the out feature map of the first layer and its input, passing it through 16 more 3 X 3 pixel filters to extract deeper features, maintaining the same stride pattern and padding. Rather than applying the the regular Relu activation function to convert negative pixels to zeros, we allow for small negative values and then normalize.
Pooling Layer
To reduce the dimensions and computational complexity of the resultant feature map from the previous layer a pooling layer is added. Here we use the 2 X 2 max pooling matrix, which scans over 2 strides. This halves the size of the feature map by selecting only the maximum weight value from each 2 x 2 jump. In order to prevent overfitting the dropout method is employed, whereby randomly dropping some neurons with each batch that passes through the layer, feature weights are allowed to average out. Here we use a drop rate of 0.25.
# Initialise model
model <- keras_model_sequential()
# Add layers
model %>%
layer_conv_2d(filter = 32, kernel_size = c(3,3), padding = "same",
input_shape = c(img_width, img_height, channels)) %>% layer_activation("relu") %>%
# Second hidden layer
layer_conv_2d(filter = 16, kernel_size = c(3,3), padding = "same") %>%
layer_activation_leaky_relu(0.5) %>%
layer_batch_normalization() %>%
# Use max pooling
layer_max_pooling_2d(pool_size = c(2,2)) %>%
layer_dropout(0.25) %>%
# Flatten max filtered output into feature vector and feed into dense layer
layer_flatten() %>%
layer_dense(200) %>%
layer_activation("relu") %>%
layer_dropout(0.5) %>%
# Outputs from dense layer are projected onto output layer
layer_dense(output_n) %>%
layer_activation("softmax")
# Compile
model %>% compile(
loss = "categorical_crossentropy",
optimizer = "SGD",
metrics = "accuracy"Dense and Outer Layers
The Dense (or fully connected) layer of the model enables the model to output a classification for the input image. In order to pass the pooling output to the dense layer, however, the multi-dimensional tensors of the pooling output must be flattened into a 1-dimensional tensor vector. The values of this vector represent the probability of a particular feature belonging to a particular classification. The output of the dense layer is then subjected to Relu activation and drop out before it is projected to the outermost layer, using the softmax activation function, to be classified as happy or sad.
Compiling the Model
Before passing our training set through the model, we needed to compile the layers built in the previous steps. Compiling the model allows us to define how best to improve the model each time a batch is passed through the network. For our model we use the stochastic gradient descent (SGD) optimizer to readjust the weights between passes, and the cross-entropy loss function to measure the model’s performance. If our model is good, we expect a smaller log loss with each pass. We also tell it to report on accuracy.
Model Testing and Validation
Our next step was to train and validate our model, which were combined into one operation using the fit_generator function, shown below. In this function we indicated the number of training images to use per batch (steps_per_epoch), which amounted to r as.integer(tain_samples/batch_size), and r as.integer(valid_samples/batch_size) for the validation images. We had the fit generator save the best version of the model after each epoch to be used in the deployment of our Shiny app later, ad well as a log of training and validation metrics for visualization, which can be seen below.
# Fit
hist <- model
%>% fit_generator( #Training data train_images,
#Epochs
steps_per_epoch = as.integer(train_samples / batch_size), epochs = epochs,
#Validation data
validation_data = valid_images,
validation_steps = as.integer(valid_samples / batch_size)))
#Print progress
verbose = 1,
callbacks = list(
#Save best model after every epoch callback_model_checkpoint("/Users/stantaov/Documents/keras/face.h5",
save_best_only = TRUE), #Only needed for visualising with TensorBoard
callback_tensorboard(log_dir = "/Users/stantaov/Documents/keras/logs"